Documentation · Examples · Discord



vectara-agentic is a Python library for developing powerful AI assistants and agents using Vectara and Agentic-RAG. It leverages the LlamaIndex Agent framework and provides helper functions to quickly create tools that connect to Vectara corpora.
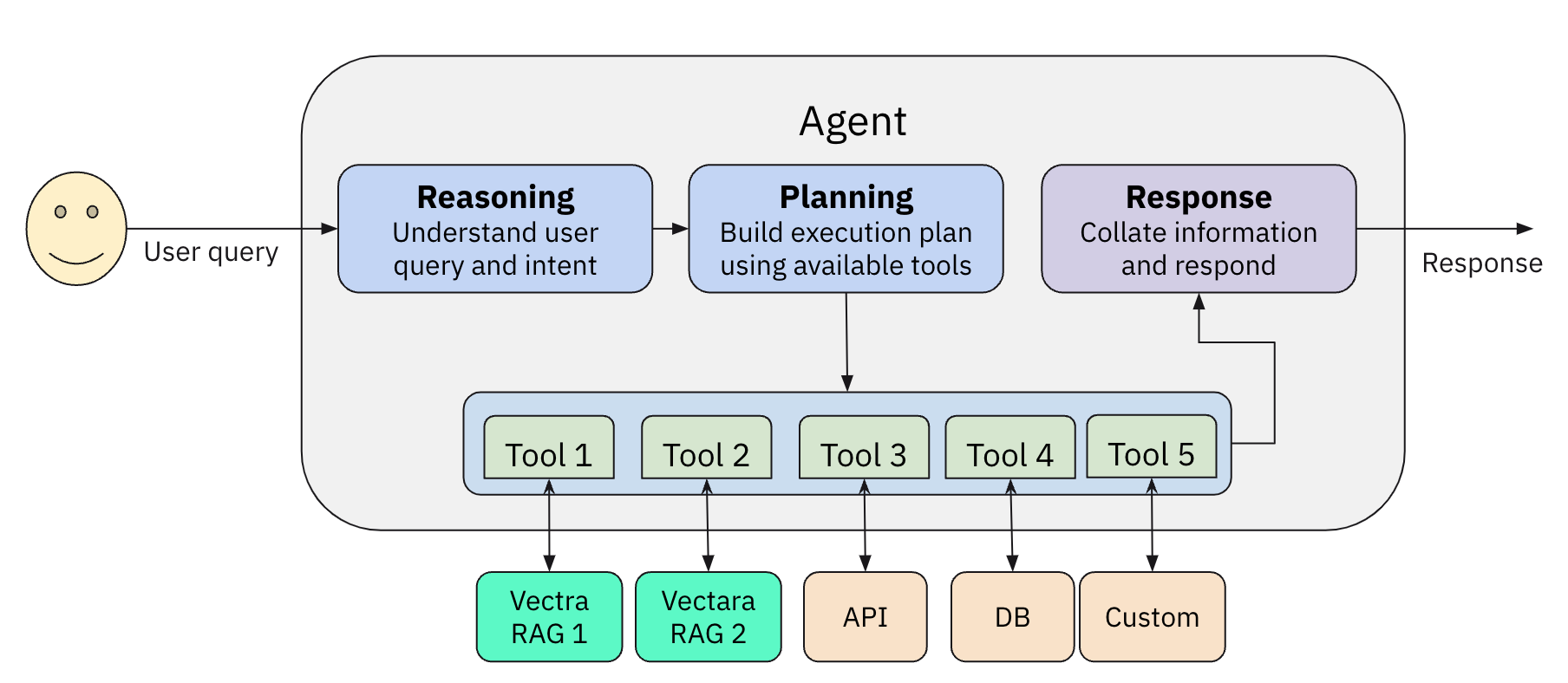
- Rapid Tool Creation:
Build Vectara RAG tools or search tools with a single line of code. - Agent Flexibility:
Supports multiple agent types includingReAct,OpenAIAgent,LATS, andLLMCompiler. - Pre-Built Domain Tools:
Tools tailored for finance, legal, and other verticals. - Multi-LLM Integration:
Seamless integration with OpenAI, Anthropic, Gemini, GROQ, Together.AI, Cohere, Bedrock, and Fireworks. - Observability:
Built-in support with Arize Phoenix for monitoring and feedback. - Workflow Support:
Extend your agent's capabilities by defining custom workflows using therun()method.
Check out our example AI assistants:
- Vectara account
- A Vectara corpus with an API key
- Python 3.10 or higher
- OpenAI API key (or API keys for Anthropic, TOGETHER.AI, Fireworks AI, Bedrock, Cohere, GEMINI or GROQ, if you choose to use them)
pip install vectara-agenticLet's see how we create a simple AI assistant to answer questions about financial data ingested into Vectara, using vectara-agentic.
import os
from vectara_agentic.tools import VectaraToolFactory
vec_factory = VectaraToolFactory(
vectara_api_key=os.environ['VECTARA_API_KEY'],
vectara_corpus_key=os.environ['VECTARA_CORPUS_KEY']
)A RAG tool calls the full Vectara RAG pipeline to provide summarized responses to queries grounded in data. We define two additional arguments (year and ticker that map to filter attributes in the Vectara corpus):
from pydantic import BaseModel, Field
years = list(range(2020, 2024))
tickers = {
"AAPL": "Apple Computer",
"GOOG": "Google",
"AMZN": "Amazon",
"SNOW": "Snowflake",
}
class QueryFinancialReportsArgs(BaseModel):
year: int | str = Field(..., description=f"The year this query relates to. An integer between {min(years)} and {max(years)} or a string specifying a condition on the year (example: '>2020').")
ticker: str = Field(..., description=f"The company ticker. Must be a valid ticket symbol from the list {tickers.keys()}.")
ask_finance = vec_factory.create_rag_tool(
tool_name="query_financial_reports",
tool_description="Query financial reports for a company and year",
tool_args_schema=QueryFinancialReportsArgs,
lambda_val=0.005,
summary_num_results=7,
# Additional Vectara query arguments...
)Note: We only defined the
yearandtickerarguments in the QueryFinancialReportsArgs model. Thequeryargument is automatically added bycreate_rag_tool.
To learn about additional arguments create_rag_tool, please see the full docs.
In addition to RAG tools or search tools, you can generate additional tools the agent can use. These could be mathematical tools, tools that call other APIs to get more information, or any other type of tool.
See Agent Tools for more information.
Here is how we will instantiate our AI Finance Assistant. First define your custom instructions:
financial_assistant_instructions = """
- You are a helpful financial assistant, with expertise in financial reporting, in conversation with a user.
- Never discuss politics, and always respond politely.
- Respond in a compact format by using appropriate units of measure (e.g., K for thousands, M for millions, B for billions).
- Do not report the same number twice (e.g. $100K and 100,000 USD).
- Always check the get_company_info and get_valid_years tools to validate company and year are valid.
- When querying a tool for a numeric value or KPI, use a concise and non-ambiguous description of what you are looking for.
- If you calculate a metric, make sure you have all the necessary information to complete the calculation. Don't guess.
"""Then just instantiate the Agent class:
from vectara_agentic import Agent
agent = Agent(
tools =
[ask_finance],
topic="10-K annual financial reports",
custom_instructions=financial_assistant_instructions,
agent_progress_callback=agent_progress_callback
)The topic parameter helps identify the agent's area of expertise, while custom_instructions lets you customize how the agent behaves and presents information. The agent will combine these with its default general instructions to determine its complete behavior.
The agent_progress_callback argument is an optional function that will be called when various Agent events occur, and can be used to track agent steps.
res = agent.chat("What was the revenue for Apple in 2021?")
print(res.response)Note:
vectara-agenticalso supportsachat()as well as two streaming variantsstream_chat()andastream_chat().- The response types from
chat()andachat()are of typeAgentResponse. If you just need the actual string response it's available as theresponsevariable, or just usestr(). For advanced use-cases you can look at otherAgentResponsevariables such assources.
When creating an agent, it already comes with a set of general base instructions, designed carefully to enhance its operation and improve how the agent works.
In addition, you can add custom_instructions that are specific to your use case that customize how the agent behaves.
When writing custom instructions:
- Focus on behavior and presentation rather than tool usage (that's what tool descriptions are for)
- Be precise and clear without overcomplicating
- Consider edge cases and unusual scenarios
- Avoid over-specifying behavior based on primary use cases
- Keep instructions focused on how you want the agent to behave and present information
The agent will combine both the general instructions and your custom instructions to determine its behavior.
It is not recommended to change the general instructions, but it is possible as well to override them with the optional general_instructions parameter. If you do change them, your agent may not work as intended, so be careful if overriding these instructions.
vectara-agentic provides two helper functions to connect with Vectara RAG:
create_rag_tool()to create an agent tool that connects with a Vectara corpus for querying.create_search_tool()to create a tool to search a Vectara corpus and return a list of matching documents.
See the documentation for the full list of arguments for create_rag_tool() and create_search_tool(),
to understand how to configure Vectara query performed by those tools.
A Vectara RAG tool is often the main workhorse for any Agentic RAG application, and enables the agent to query one or more Vectara RAG corpora.
The tool generated always includes the query argument, followed by 1 or more optional arguments used for
metadata filtering, defined by tool_args_schema.
For example, in the quickstart example the schema is:
class QueryFinancialReportsArgs(BaseModel):
year: int | str = Field(..., description=f"The year this query relates to. An integer between {min(years)} and {max(years)} or a string specifying a condition on the year (example: '>2020').")
ticker: str = Field(..., description=f"The company ticker. Must be a valid ticket symbol from the list {tickers.keys()}.")Remember, the query argument is part of the rag_tool that is generated, but vectara-agentic creates it and you do
not need to specify it explicitly.
For example, in the example above, the agent may call the query_financial_reports_tool tool with
query='what is the revenue?', year=2022 and ticker='AAPL'. Subsequently the RAG tool will issue
a Vectara RAG query with the same query, but with metadata filtering (doc.year=2022 and doc.ticker='AAPL').
There are also additional cool features supported here:
- An argument can be a condition, for example year='>2022' translates to the correct metadata filtering condition doc.year>2022
- if
fixed_filteris defined in the RAG tool, it provides a constant metadata filtering that is always applied. For example, if fixed_filter=doc.filing_type='10K'then a query with query='what is the reveue', year=2022 and ticker='AAPL' would translate into query='what is the revenue' with metadata filtering condition of "doc.year=2022 AND doc.ticker='AAPL' and doc.filing_type='10K'"
Note that tool_args_type is an optional dictionary that indicates the level at which metadata filtering
is applied for each argument (doc or part)
The Vectara search tool allows the agent to list documents that match a query. This can be helpful to the agent to answer queries like "how many documents discuss the iPhone?" or other similar queries that require a response in terms of a list of matching documents.
vectara-agentic provides a few tools out of the box (see ToolsCatalog for details):
1. Standard tools
summarize_text: a tool to summarize a long text into a shorter summary (uses LLM)rephrase_text: a tool to rephrase a given text, given a set of rephrase instructions (uses LLM)
These tools use an LLM and so would use the Tools LLM specified in your AgentConfig.
To instantiate them:
from vectara_agentic.tools_catalog import ToolsCatalog
summarize_text = ToolsCatalog(agent_config).summarize_textThis ensures the summarize_text tool is configured with the proper LLM provider and model as specified in the Agent configuration.
2. Legal tools A set of tools for the legal vertical, such as:
summarize_legal_text: summarize legal text with a certain point of viewcritique_as_judge: critique a legal text as a judge, providing their perspective
3. Financial tools Based on tools from Yahoo! Finance:
- tools to understand the financials of a public company like:
balance_sheet,income_statement,cash_flow stock_news: provides news about a companystock_analyst_recommendations: provides stock analyst recommendations for a company.
4. Database tools Providing tools to inspect and query a database:
list_tables: list all tables in the databasedescribe_tables: describe the schema of tables in the databaseload_data: returns data based on a SQL queryload_sample_data: returns the first 25 rows of a tableload_unique_values: returns the top unique values for a given column
5. Additional integrations vectara-agentic includes various other tools from LlamaIndex ToolSpecs:
-
Search Tools
- Tavily Search: Real-time web search using Tavily API
from vectara_agentic.tools_catalog import ToolsCatalog tavily_tool = ToolsCatalog(agent_config).tavily_search
- EXA.AI: Advanced web search and data extraction
exa_tool = ToolsCatalog(agent_config).exa_search
- Brave Search: Web search using Brave's search engine
brave_tool = ToolsCatalog(agent_config).brave_search
- Tavily Search: Real-time web search using Tavily API
-
Academic Tools
- arXiv: Search and retrieve academic papers
arxiv_tool = ToolsCatalog(agent_config).arxiv_search
- arXiv: Search and retrieve academic papers
-
Graph Database Tools
- Neo4j: Graph database integration
neo4j_tool = ToolsCatalog(agent_config).neo4j_query
- Kuzu: Lightweight graph database
kuzu_tool = ToolsCatalog(agent_config).kuzu_query
- Neo4j: Graph database integration
-
Google Tools
- Gmail: Read and send emails
gmail_tool = ToolsCatalog(agent_config).gmail
- Calendar: Manage calendar events
calendar_tool = ToolsCatalog(agent_config).calendar
- Search: Google search integration
google_search_tool = ToolsCatalog(agent_config).google_search
- Gmail: Read and send emails
-
Communication Tools
- Slack: Send messages and interact with Slack
slack_tool = ToolsCatalog(agent_config).slack
- Slack: Send messages and interact with Slack
For detailed setup instructions and API key requirements, please refer the instructions on LlamaIndex hub for the specific tool.
You can create your own tool directly from a Python function using the create_tool() method of the ToolsFactory class:
def mult_func(x, y):
return x * y
mult_tool = ToolsFactory().create_tool(mult_func)Important: When you define your own Python functions as tools, implement them at the top module level, and not as nested functions. Nested functions are not supported if you use serialization (dumps/loads or from_dict/to_dict).
When creating an agent, you can enable tool validation by setting validate_tools=True. This will check that any tools mentioned in your custom instructions actually exist in the agent's tool set:
agent = Agent(
tools=[...],
topic="financial reports",
custom_instructions="Always use the get_company_info tool first...",
validate_tools=True # Will raise an error if get_company_info tool doesn't exist
)This helps catch errors where your instructions reference tools that aren't available to the agent.
In addition to standard chat interactions, vectara-agentic supports custom workflows via the run() method.
Workflows allow you to structure multi-step interactions where inputs and outputs are validated using Pydantic models.
To learn more about workflows read the documentation
Workflows provide a structured way to handle complex, multi-step interactions with your agent. They're particularly useful when:
- You need to break down complex queries into simpler sub-questions
- You want to implement a specific sequence of operations
- You need to maintain state between different steps of a process
- You want to parallelize certain operations for better performance
Create a workflow by subclassing llama_index.core.workflow.Workflow and defining the input/output models:
from pydantic import BaseModel
from llama_index.core.workflow import (
StartEvent, StopEvent, Workflow, step,
)
class MyWorkflow(Workflow):
class InputsModel(BaseModel):
query: str
class OutputsModel(BaseModel):
answer: str
@step
async def my_step(self, ev: StartEvent) -> StopEvent:
# do something here
return StopEvent(result="Hello, world!")When the run() method in vectara-agentic is invoked, it calls the workflow with the following variables in the StartEvent:
agent: the agent object used to callrun()(self)tools: the tools provided to the agent. Those can be used as needed in the flow.llm: a pointer to a LlamaIndex llm, so it can be used in the workflow. For example, one of the steps may callllm.acomplete(prompt)verbose: controls whether extra debug information is displayedinputs: this is the actual inputs to the workflow provided by the call torun()and must be of typeInputsModel
If you want to use agent, tools, llm or verbose in other events (that are not StartEvent), you can store them in
the Context of the Workflow as follows:
await ctx.set("agent", ev.agent)and then in any other event you can pull that agent object with
agent = await ctx.get("agent")Similarly you can reuse the llm, tools or verbose arguments within other nodes in the workflow.
When initializing your agent, pass the workflow class using the workflow_cls parameter:
agent = Agent(
tools=[query_financial_reports_tool],
topic="10-K financial reports",
custom_instructions="You are a helpful financial assistant.",
workflow_cls=MyWorkflow, # Provide your custom workflow here
workflow_timeout=120 # Optional: Set a timeout (default is 120 seconds)
)Prepare the inputs using your workflow's InputsModel and execute the workflow using run():
# Create an instance of the workflow's input model
inputs = MyWorkflow.InputsModel(query="What is Vectara?", extra_param=42)
# Run the workflow (ensure you're in an async context or use asyncio.run)
workflow_result = asyncio.run(agent.run(inputs))
# Access the output from the workflow's OutputsModel
print(workflow_result.answer)vectara-agentic includes two workflow implementations that you can use right away:
This workflow breaks down complex queries into simpler sub-questions, executes them in parallel, and then combines the answers:
from vectara_agentic.sub_query_workflow import SubQuestionQueryWorkflow
agent = Agent(
tools=[query_financial_reports_tool],
topic="10-K financial reports",
custom_instructions="You are a helpful financial assistant.",
workflow_cls=SubQuestionQueryWorkflow
)
# Run the workflow with a complex query
inputs = SubQuestionQueryWorkflow.InputsModel(
query="Compare Apple's revenue growth to Google's between 2020 and 2023"
)
result = asyncio.run(agent.run(inputs))
print(result.response)The workflow works in three steps:
- Query: Breaks down the complex query into sub-questions
- Sub-question: Executes each sub-question in parallel (using 4 workers by default)
- Combine answers: Synthesizes all the answers into a coherent response
This workflow is similar to SubQuestionQueryWorkflow but executes sub-questions sequentially, where each question can depend on the answer to the previous question:
from vectara_agentic.sub_query_workflow import SequentialSubQuestionsWorkflow
agent = Agent(
tools=[query_financial_reports_tool],
topic="10-K financial reports",
custom_instructions="You are a helpful financial assistant.",
workflow_cls=SequentialSubQuestionsWorkflow
)
# Run the workflow with a complex query that requires sequential reasoning
inputs = SequentialSubQuestionsWorkflow.InputsModel(
query="What was the revenue growth rate of the company with the highest market cap in 2022?"
)
result = asyncio.run(agent.run(inputs))
print(result.response)The workflow works in two steps:
- Query: Breaks down the complex query into sequential sub-questions
- Sub-question: Executes each sub-question in sequence, passing the answer from one question to the next
-
Use SubQuestionQueryWorkflow when:
- Your query can be broken down into independent sub-questions
- You want to parallelize the execution for better performance
- The sub-questions don't depend on each other's answers
-
Use SequentialSubQuestionsWorkflow when:
- Your query requires sequential reasoning
- Each sub-question depends on the answer to the previous question
- You need to build up information step by step
-
Create a custom workflow when:
- You have a specific sequence of operations that doesn't fit the built-in workflows
- You need to implement complex business logic
- You want to integrate with external systems or APIs in a specific way
The main way to control the behavior of vectara-agentic is by passing an AgentConfig object to your Agent when creating it.
For example:
from vectara_agentic import AgentConfig, AgentType, ModelProvider
agent_config = AgentConfig(
agent_type = AgentType.REACT,
main_llm_provider = ModelProvider.ANTHROPIC,
main_llm_model_name = 'claude-3-5-sonnet-20241022',
tool_llm_provider = ModelProvider.TOGETHER,
tool_llm_model_name = 'meta-llama/Llama-3.3-70B-Instruct-Turbo'
)
agent = Agent(
tools=[query_financial_reports_tool],
topic="10-K financial reports",
custom_instructions="You are a helpful financial assistant in conversation with a user.",
agent_config=agent_config
)The AgentConfig object may include the following items:
agent_type: the agent type. Valid values areREACT,LLMCOMPILER,LATSorOPENAI(default:OPENAI).main_llm_providerandtool_llm_provider: the LLM provider for main agent and for the tools. Valid values areOPENAI,ANTHROPIC,TOGETHER,GROQ,COHERE,BEDROCK,GEMINIorFIREWORKS(default:OPENAI).main_llm_model_nameandtool_llm_model_name: agent model name for agent and tools (default depends on provider).observer: the observer type; should beARIZE_PHOENIXor if undefined no observation framework will be used.endpoint_api_key: a secret key if using the API endpoint option (defaults todev-api-key)max_reasoning_steps: the maximum number of reasoning steps (iterations for React and function calls for OpenAI agent, respectively). Defaults to 50.
If any of these are not provided, AgentConfig first tries to read the values from the OS environment.
When creating a VectaraToolFactory, you can pass in a vectara_api_key, and vectara_corpus_key to the factory.
If not passed in, it will be taken from the environment variables (VECTARA_API_KEY and VECTARA_CORPUS_KEY). Note that VECTARA_CORPUS_KEY can be a single KEY or a comma-separated list of KEYs (if you want to query multiple corpora).
These values will be used as credentials when creating Vectara tools - in create_rag_tool() and create_search_tool().
If you want to setup vectara-agentic to use your own self-hosted LLM endpoint, follow the example below:
from vectara_agentic import AgentConfig, AgentType, ModelProvider
config = AgentConfig(
agent_type=AgentType.REACT,
main_llm_provider=ModelProvider.PRIVATE,
main_llm_model_name="meta-llama/Meta-Llama-3.1-8B-Instruct",
private_llm_api_base="http://vllm-server.company.com/v1",
private_llm_api_key="TEST_API_KEY",
)
agent = Agent(
agent_config=config,
tools=tools,
topic=topic,
custom_instructions=custom_instructions
)